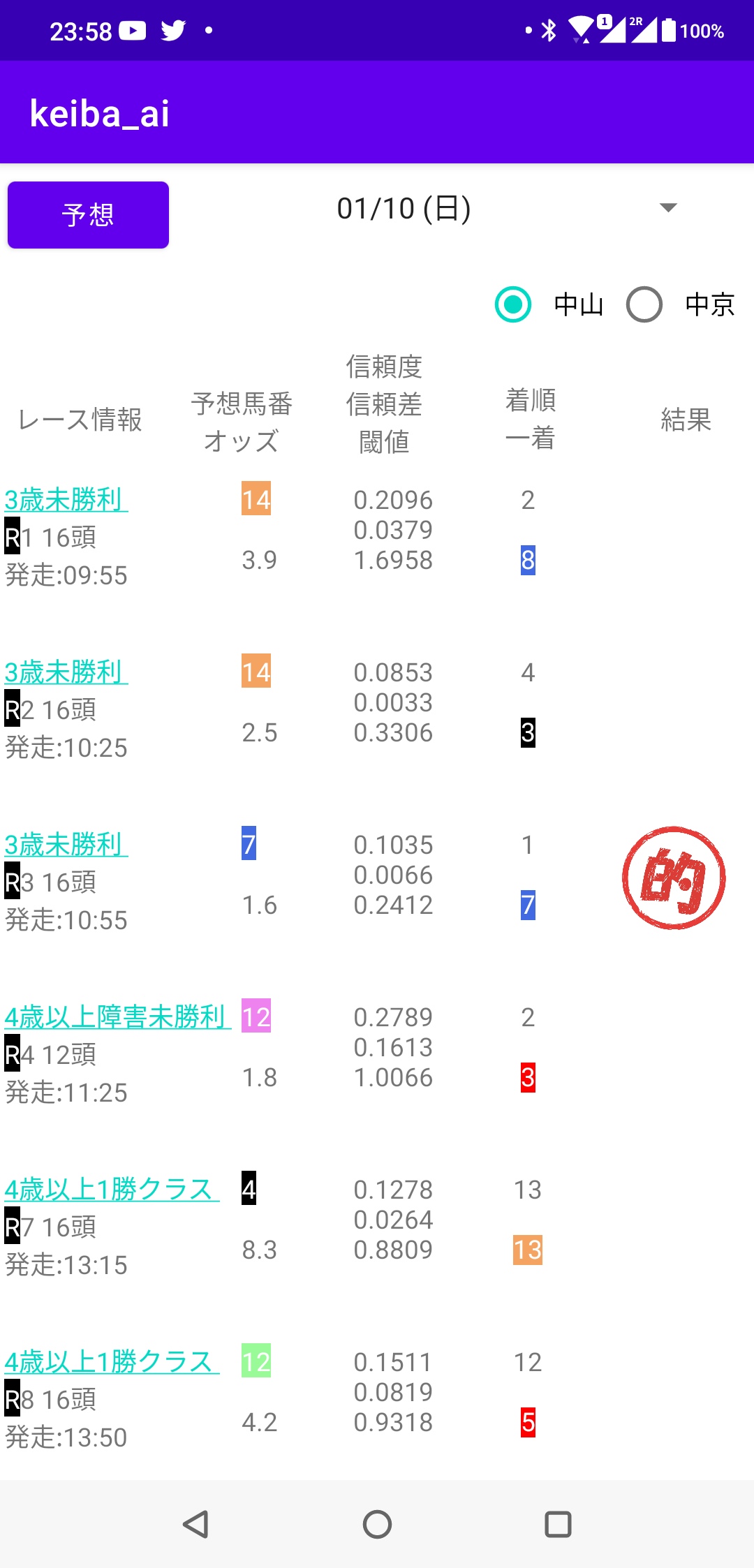
| レース名 | Round | 発走 | 頭数 | 予想馬番 | オッズ | 信頼度 | 信頼差 | 閾値 | 着順 | 一着 | 結果 |
|---|
予想レース
レース30分前公開
競馬場現在天気
過去レース
過去一年分レース結果
信頼度
馬が一着の確率です。
信頼差
信頼度が一番高い馬と二番目高い馬の信頼度の差。
閾値
計算式
信頼差 * 2 + 信頼度 * オッズ * 1.2
重みの決め方は前年度レースのシミュレーションの結果で決めます。
この閾値で馬券買うか買わないかで決めます。
結果統計
一年間内、閾値1.5以上のみ集計。
競馬場回収率
閾値回収率
競馬場勝率
閾値勝率
競馬場レース数
閾値レース数
使用技術
言語、フレームワーク
Python3
ライブラリ Seleniumでブラウザを操作し、10年分のデータをWEBスクレイピンで収集します。
ライブラリ Pandasでデータを整形します。
LightGBM
LightGBM(読み:ライト・ジービーエム)決定木アルゴリズムに基づいた勾配ブースティング(Gradient Boosting)の機械学習フレームワークです。LightGBMは米マイクロソフト社2016年にリリースされました。
Kotlin
App版はkotlinで作りました。WebAPI使って、DBサーバ内のデータを取得、アプリで現在の予想馬番が見れます。
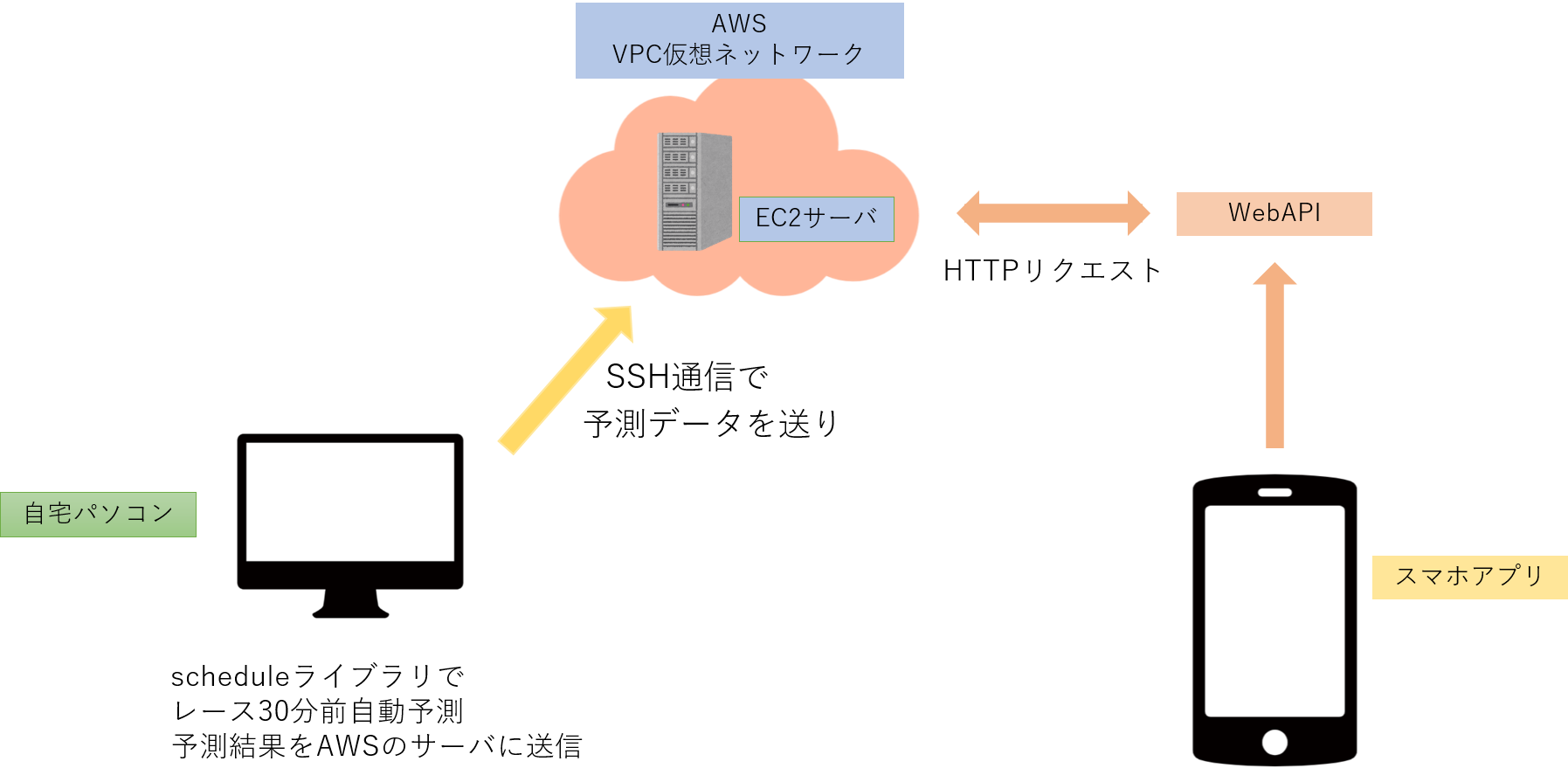
システム構成
本サイトはAWS EC2でWEBサーバを構築しています。
アプリ APK ダウンロード
Download実際の画面

モデル訓練
使用の特徴量、学習に使ったフレームワーク。
特徴量
天気、コース、距離、前5走までのレース情報、5代血統、騎手、調教師、タイム指数、本賞金など全部
300個以上の特徴量を使いました。
中には本賞金は重要な影響があり、本賞金はレースのレベル直接に関係があり、そのレースの着順でその馬の強さを数値化できます。
オッズと人気はあえて使わない、その理由は回収率が下がります。オッズ使うなら、勝率は上がるが、予想した馬は人気上位ばかりので、オッズ的にはあまり美味しくないです。
フレームワーク
最初はディープラーニングのKerasを使いましたが、パラメータの設定には複雑ので断念しました。その後マイクロソフト社のLightGBMを切り替えました。LightGBMはKaggleに人気なフレームワークで、ネット上も色んなリソースがあります。その上使いやすいし、訓練時間も短いし、とてもおすすめです。
そしてフレームワークOptunaを使ってハイパーパラメータを自動にチュウニングして、最低限のパラメータ設定すればいいです。
工夫した所
データの整形は一番力入れたところです。訓練にするため、全部のデータを数値型に変更しなければならないので、カテゴリ種類が少ない特徴量(例:天気、コース距離、コース種類)ならば、OneHotEncoderでいけますが、馬、騎手、調教師、血統ようなカテゴリの数がとても多い場合、Target Encoding(目的変数の平均値)で変更します。つまりこの場合は、馬、騎手、調教師の特徴量をそれぞれの勝率に変更することです。
私は勝率を計算の時、一つの罠にはまった、それは未来のデータを使いました。正しい計算はそのレース前のレースのみで勝率を計算することです。そのためデータの整形はとても大変です、多くの時間をデータの整形に費やしました。
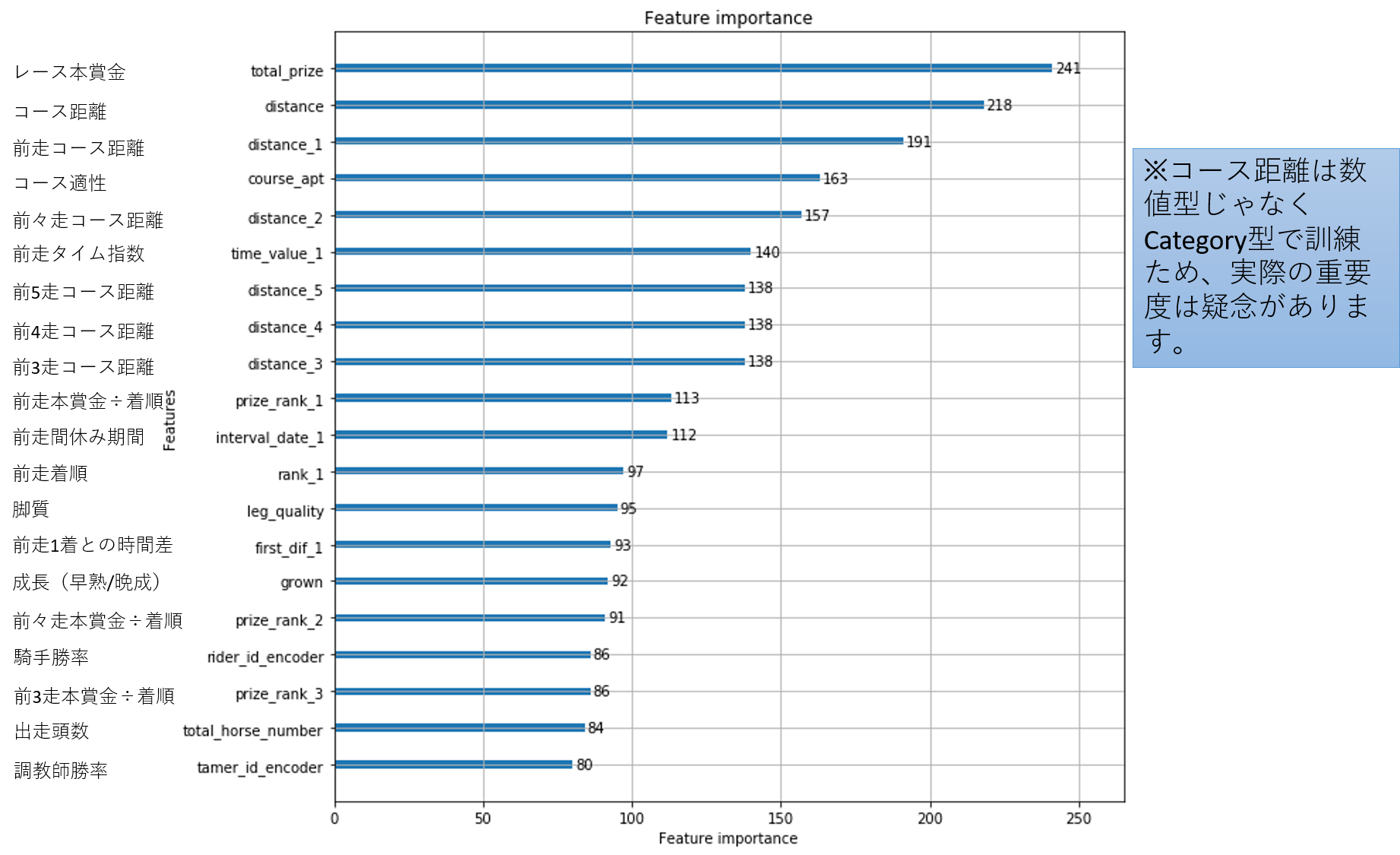
特徴量重要度
予想に使った特徴量は全部300個があります。下の図は重要度の高い上位20の特徴量です。
馬券自動購入
スクリプトDL実際の動作
scheduleライブラリでレース5分前自動予測して、閾値が予め決めた数値以上であれば自動に馬券を購入します。